토이프로젝트 정리 노트, 3부작 중 마지막. 직접 수집한 라이브 L2 호가창 스냅샷 약 5만 4천 장(Binance
depth20@100ms, BTCUSDT·ETHUSDT 각 ~2만 7천, 약 45분). 다음 순간 가격 방향을 3-class로 맞히는 문제. 코드는 repo. 1편·2편에 이어, 금융 배경 없이 읽도록 썼다.
호가창(order book)은 지금 이 종목을 사려는 사람들의 가격·수량과 팔려는 사람들의 가격·수량을 줄 세운 목록이다. 양쪽 균형이 어디로 기우는지를 보면 다음 순간 가격이 어디로 갈지 짐작할 수 있다. 그 기울기를 한 숫자로 요약한 게 order flow imbalance(OFI), 짧은 시간 동안 들어오고 빠진 매수·매도 주문의 불균형이다.
OFI가 호가창의 충분통계량인지를 보고 싶었다. 충분통계량이라는 건, OFI만 있으면 호가창 원본을 다시 안 봐도 예측에 필요한 정보가 다 들어 있다는 뜻이다. 결론부터 말하면 아니었다. 호가창 원본이 이겼고, 호가창을 단 한 장 본 모델이 20장을 본 LSTM을 전부 이겼다.
낚이지 않으려고 분석 전에 질문 셋을 먼저 고정했다. 결과를 보고 이야기를 짜맞추는 걸 막기 위해서다.
- Q1. 호가창 깊이가 도움이 되나 (다단계 OFI vs 최우선 1단계 OFI)
- Q2. 흐름이 상태를 대신하나 (OFI vs 원본 호가창)
- Q3. 흐름이 상태에 보탬이 되나 (원본 + OFI vs 원본)
Q1. 호가창 깊이가 도움이 되나
다단계 OFI가 1단계 OFI보다 8개 칸 중 5개에서 나았다. 다만 예측 구간에 따라 갈렸다. 짧은 구간(k=10, 20)에서는 깊은 호가의 압력이 분명히 도움이 됐고, 가장 긴 구간(k=100)에서는 최우선 호가 하나만으로 충분하거나 오히려 나았다(BTC k=100: 1단계 0.451 vs 다단계 0.383). 멀리 보는 움직임은 호가창 맨 위에서 결정된다는 쪽이다.
Q2. 흐름이 상태를 대신하나
핵심 질문이다. 먼저 스냅샷 한 장을 그대로 넣는 정적 모델(로지스틱, 작은 MLP)로 붙였다. 입력별 최고 점수만 추리면 이렇다.
| 입력 (정적 최고) | BTC k=20 | BTC k=50 | ETH k=20 | ETH k=50 |
|---|---|---|---|---|
| OFI 1단계 | 0.311 | 0.380 | 0.346 | 0.398 |
| OFI 전단계 | 0.368 | 0.373 | 0.362 | 0.400 |
| 원본 호가창 | 0.404 | 0.402 | 0.432 | 0.448 |
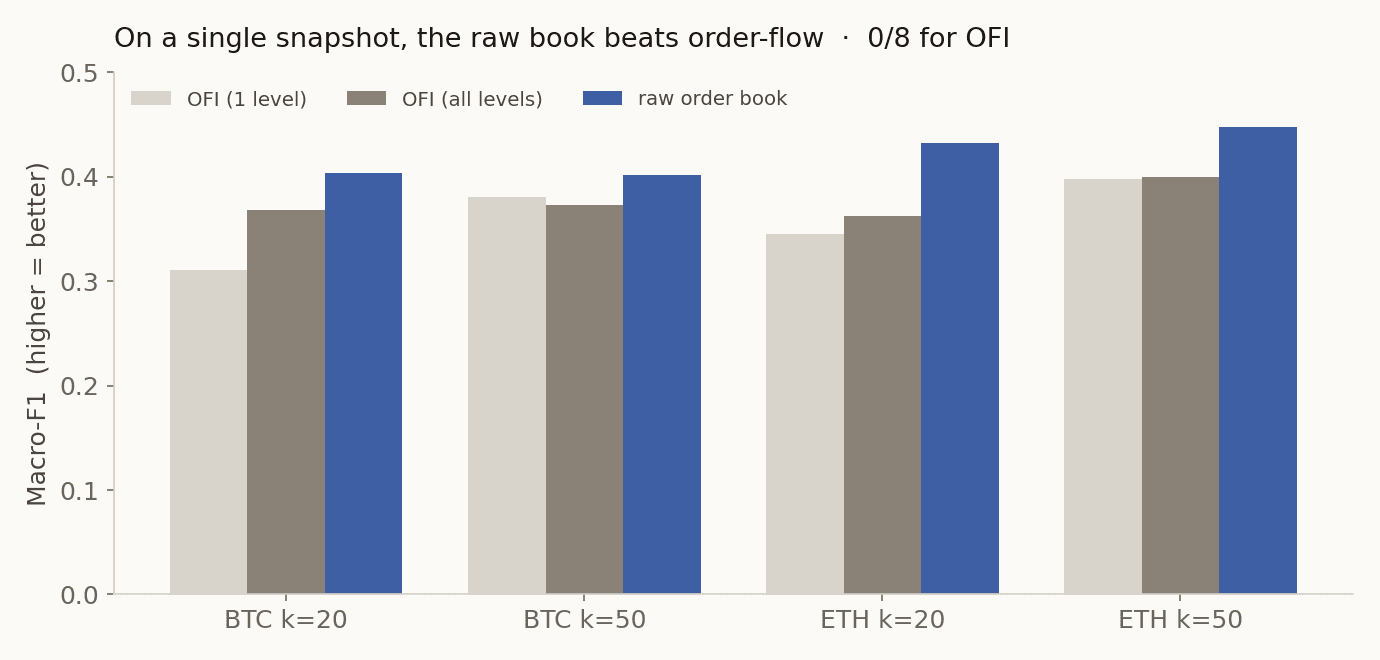
8개 칸 전부에서 원본 호가창이 이겼다. OFI가 0:8이다. 이유는 단순하다. 원본 호가창 벡터에는 지금 이 순간 최우선 호가의 대기 물량 불균형, 즉 queue imbalance가 들어 있다. 단기 가격 방향을 가장 잘 맞히는 걸로 알려진 변수인데, 일정 시간 창으로 합산한 '흐름' 측정치인 OFI에는 이 순간 상태가 직접 담기지 않는다. 정적 특징으로서 OFI는 충분통계량이 아니다.
여기서 시계열 모델로 넘어가면 그림이 뒤집히는 것처럼 보인다. 지난 20장을 LSTM에 넣으면 OFI 시퀀스(20차원)가 원본 시퀀스(80차원)를 4칸 중 4칸에서 이긴다. 흐름이 이기는 것처럼 보인다. 그런데 이건 표현의 승리가 아니라 모델 용량의 착시였고, 통제 하나가 그걸 드러낸다.
원본 시퀀스는 입력 폭이 4배(80 vs 20)다. 작은 LSTM이 그 넓은 입력을 제대로 학습 못 하고 underfit한다. 그래서 원본 시퀀스를 PCA로 OFI와 같은 20차원으로 압축해서 다시 넣어봤다.
| 칸 | OFI 시퀀스 (20차원) | 원본 시퀀스 (80차원) | 원본 → PCA 20차원 |
|---|---|---|---|
| BTC k=50 | 0.399 | 0.376 | 0.391 |
| BTC k=100 | 0.374 | 0.363 | 0.375 |
| ETH k=50 | 0.373 | 0.344 | 0.363 |
| ETH k=100 | 0.357 | 0.326 | 0.328 |
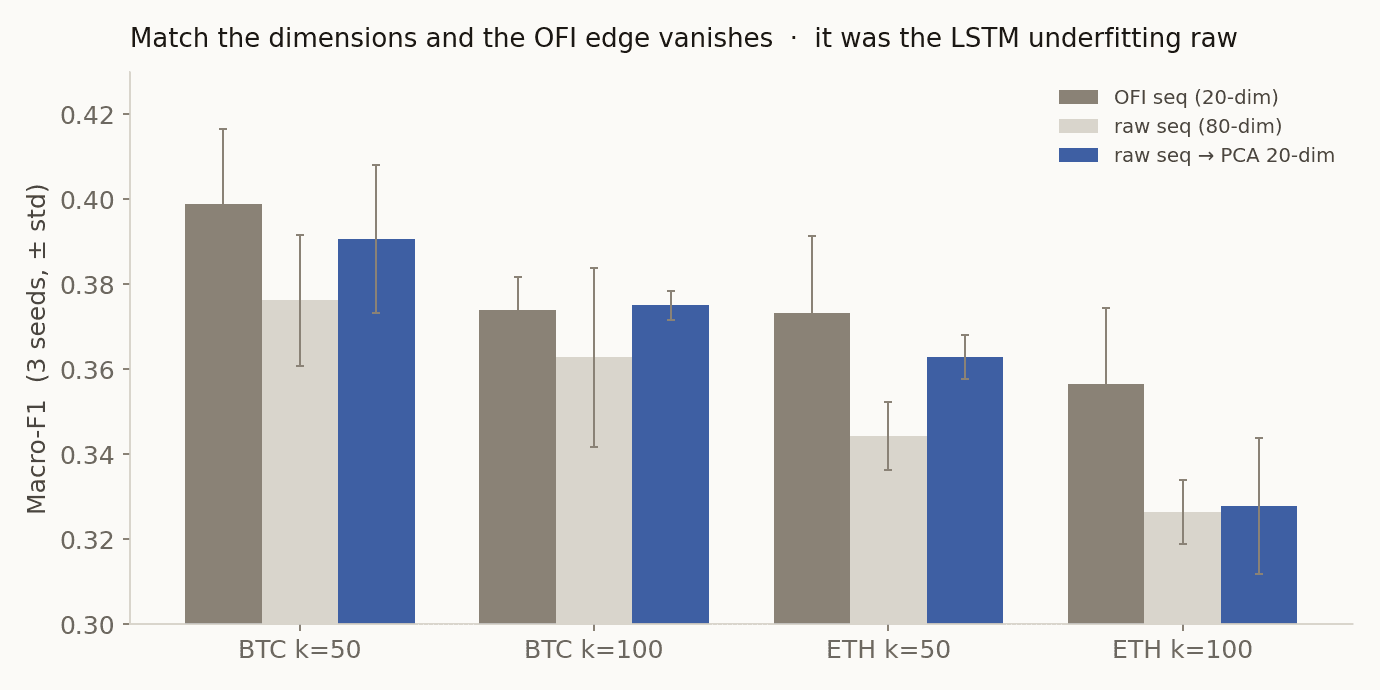
차원을 맞추자 OFI와 원본은 비긴다(셋은 노이즈 안, 잔여 우위는 ETH k=100 한 칸뿐). OFI가 더 나은 표현이 아니라, 호가창을 정보 손실 없이 20차원으로 압축한 것에 가깝고 그 압축은 PCA와 비슷한 수준이다. 그리고 이 연구에서 제일 잘 맞힌 모델은 따로 있다. 스냅샷 한 장을 본 정적 모델(0.400.45)이 네 칸 전부에서 모든 LSTM(0.330.40)을 이겼다. 호가창 한 장이 20장의 시퀀스를 이긴다.
Q3. 흐름이 상태에 보탬이 되나
원본 호가창 위에 OFI를 더 얹어봤다. 정적 모델에서 8개 칸 중 1개만, 그것도 미미하게 나아졌다. 흐름의 정보는 이미 호가창 상태에 거의 들어 있어서, 보탬이 되지 않는다.
그래서
가설은 기각됐다. OFI는 호가창의 충분통계량도, 호가창보다 나은 표현도 아니다. 가장 강하면서 가장 단순한 예측자는 원본 호가창, 정확히는 그 순간의 queue imbalance 상태였다. 시퀀스도 필요 없이 스냅샷 한 장이면 OFI든 LSTM이든 다 이긴다. OFI의 진짜 쓸모는 표현력이 아니라 경제성이다. 20차원 흐름 벡터가 80차원 호가창의 20차원 압축본 정도는 한다.
이건 통제된 음의 결과다. 값어치는 "ML이 호가창을 이긴다"가 아니라, 사전 등록과 용량 통제로 "OFI가 충분통계량이라는 그럴듯한 이야기가 왜 깨지는지", 그리고 표현의 차이와 모델 용량의 착시를 어떻게 구분하는지를 보인 데 있다. 모든 모델은 다수 클래스 베이스라인(F1 0.190.29)을 넘겼다(0.330.45). 100ms 유동성 높은 크립토에서 예상되는 만큼, 예측 가능성은 진짜지만 작다.
정직성 메모. 미래 차단(피처는 t 이하, 레이블은 미래, 단일 시간 분할, 스케일러는 train만), Q1·Q2·Q3와 레이블 밴드를 결과 보기 전에 고정, 박빙이던 LSTM은 시드 여러 개로 밴드까지 보고. 수집 창에 약한 하락 드리프트가 있어 긴 구간 레이블이 '하락'으로 기운다. 모든 입력에 똑같이 작용하니 비교는 안 흔들리지만, 정확도 대신 macro-F1을 쓴 이유가 이것이다.
남는 것
45분짜리 창 하나, 크립토 두 쌍이다. 다일·다종목 연구가 아니다. 100ms 클럭으로 근사한 OFI는 진짜 틱 데이터(LOBSTER)면 더 날카로워질 거고, 더 큰 시퀀스 모델(DeepLOB 같은 temporal CNN)이나 이벤트 시간 축으로 가면 시퀀스 모델이 정적 모델을 따라잡을지도 모른다. 한 종목으로 학습해 다른 종목에서 테스트하는 전이도 안 해봤다. 호가창 한 장의 우위가 그 조건에서도 버틸지는, 지금 데이터로는 모른다.
세 프로젝트 내내 같은 모양이 반복됐다. 변동성 크기는 HAR, 비용 낮은 헤지는 Black-Scholes, 단기 방향은 원본 호가창. 신경망은 교과서 가정이 깨지는 좁은 자리에서만 값을 했다. 그 자리가 어디까지 넓어지는지가, 다음에 가지고 갈 질문이다.
Data: ~54k live L2 snapshots (Binance depth20@100ms, BTCUSDT + ETHUSDT, ~27k each, ~45 min). 3-class mid-direction at horizons k ∈ , fixed ±0.3 bp band. Leak-free temporal split (last 30% test), scaler fit on train only. Metric: macro-F1. Q1/Q2/Q3 pre-registered; LSTM multi-seeded (3), static models deterministic.