토이프로젝트 정리 노트, 3부작 중 1편. SPY·QQQ·AAPL 15년치 일봉(2011–2026), Garman-Klass 실현변동성 타깃, 미래 데이터를 절대 안 쓰는 walk-forward 검증. 코드는 repo. 금융 배경지식 없이 읽도록 썼다.
먼저 결론. 변동성의 '크기'를 맞히는 시합에서 신경망(LSTM)도 부스팅 트리(XGBoost)도 변수 셋짜리 단순 회귀식 HAR을 못 이겼다. 신경망이 이긴 건 딱 하나, 변동성이 내일 오를지 내릴지 '방향'이었다.
변동성은 가격이 얼마나 사납게 움직이는지를 숫자로 바꾼 것이다. 잔잔하면 낮고, 폭락이나 폭등이 오면 치솟는다. 주가가 100에서 102로 가든 98로 가든 "2% 움직였다"는 사실만 세고, 위아래 방향은 따지지 않는다. 아래가 SPY(미국 S&P500 ETF)의 실현변동성 15년치다.
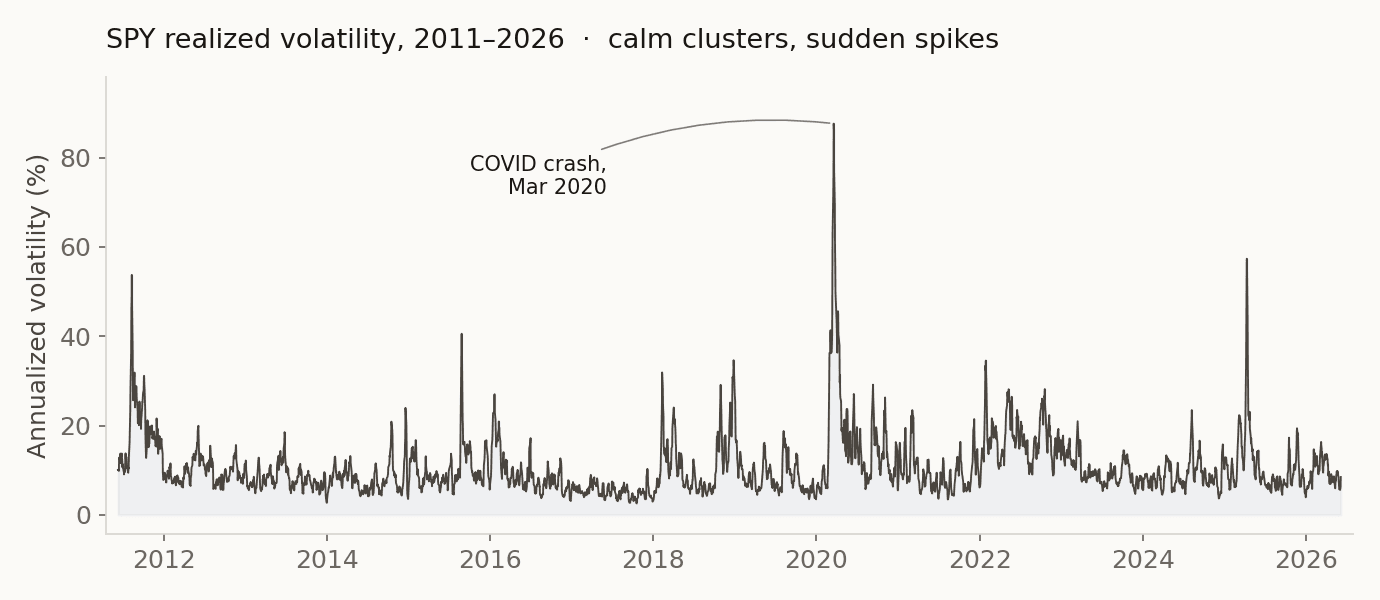
왜 이걸 예측하나. 변동성은 옵션 가격과 위험 한도의 핵심 입력값이다. 내일이 잔잔할지 거칠지 알면 가격도 위험관리도 나아진다. 이 노트는 그 숫자를 예측하는 이야기고, 2편은 이 숫자로 옵션을 헤지하는 이야기다.
채점판
모델 여섯을 붙였다. 그냥 "내일 = 오늘"이라 우기는 RandomWalk, 고전 통계 셋(EWMA, GARCH, HAR), 머신러닝 둘(XGBoost, LSTM).
| 모델 | RMSE ↓ | QLIKE ↓ | 방향 정확도 ↑ |
|---|---|---|---|
| HAR | 0.0735 | 0.3484 | 68.0% |
| XGBoost | 0.0738 | 0.3536 | 69.2% |
| LSTM | 0.0771 | 0.3728 | 70.5% |
| GARCH(1,1) | 0.1013 | 0.4289 | 58.9% |
| EWMA | 0.0902 | 0.4556 | 63.3% |
| RandomWalk | 0.0839 | 0.5815 | 0% |
QLIKE는 변동성 예측 오차를 재는 표준 점수로 낮을수록 정확하다. 방향 정확도는 변동성이 오를지 내릴지를 맞힌 비율이다. RandomWalk는 변화를 아예 예측하지 않으니 방향 점수가 0으로 박힌다.
읽는 법은 단순하다. 크기를 재는 QLIKE와 RMSE는 HAR이 1위, XGBoost가 거의 붙어서 2위, LSTM이 조금 뒤. 방향은 LSTM(70.5%), XGBoost(69.2%), HAR(68.0%) 순으로 신경망이 앞선다. 예측 구간을 하루에서 한 주(5일)로 늘려도 순서는 그대로다. 크기는 HAR, 방향은 LSTM.
신경망이 변동성 같은 비선형 시계열 문제에서 고전 회귀를 당연히 바를 거라 생각했다. 크기에서는 그러지 않았다.
단순한 게 왜 이기나
HAR은 변수가 셋뿐인 회귀식이다. 어제 하루치 변동성, 지난 한 주 평균, 지난 한 달 평균. 이 셋으로 내일을 맞힌다. 변동성이 뭉쳐서 천천히 식는 성질(위 그래프의 그 뭉침)을 거의 그대로 옮겨 담은 식이라, 통계 쪽에서 "HAR은 깨기 어렵다"는 게 정설이다.
XGBoost 속을 열어봤다. 14개 변수를 자유롭게 골라 쓸 수 있는 모델이 결국 무엇에 제일 많이 기댔는지.
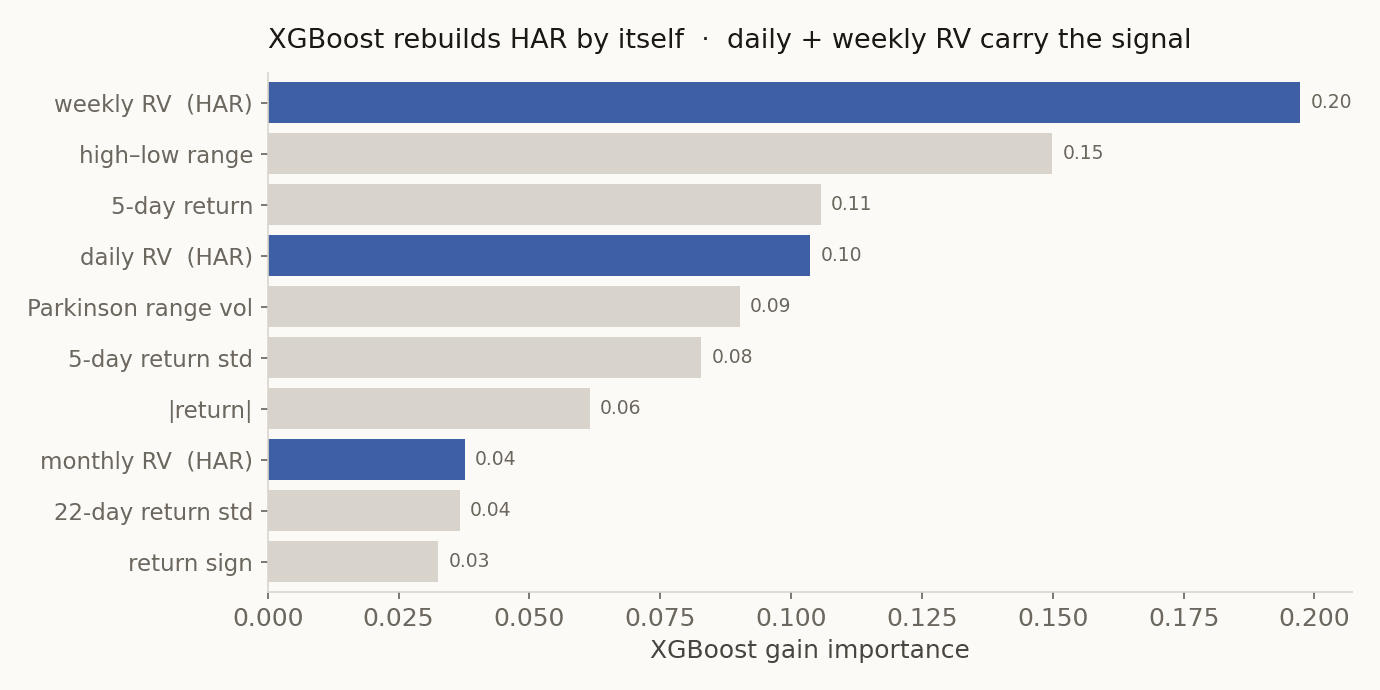
자유롭게 고를 수 있었는데도 XGBoost는 HAR이 미리 짚어둔 일·주 변동성에 제일 크게 기댔다. 스스로 HAR을 재발견한 셈이다. 신경망과 트리가 HAR을 못 이긴다기보다, HAR이 이미 정답에 가까워서 더 짜낼 여지가 없었다고 보는 쪽이 맞다. 만약 ML이 HAR을 크게 발랐다면 나는 성능을 기뻐하기 전에 데이터 누수(look-ahead)부터 의심했을 거다.
ML이 이긴 한 곳
방향은 달랐다. LSTM 70.5%, HAR 68.0%. 2.5%p 차이가 작아 보여도, 변동성이 오를지 내릴지에 베팅하는 자리(베가, variance swap 포지션)에서는 크기 맞히기보다 방향 맞히기가 돈이 된다. 크기는 HAR에 맡기고 방향 신호만 신경망에서 뽑는 조합이 자연스러운데, 이게 실제로 더 나은지는 방향만 거래하는 백테스트로 따로 확인해야 한다. 다음 메모에서 확인할 것.
내 추측인데, 신경망이 방향에서만 앞서는 건 곧 터질 것 같은 비선형 전조(좁아지던 변동성이 갑자기 벌어지는 패턴)를 트리나 회귀보다 조금 더 잡아내기 때문으로 보인다. 확신은 없다.
숫자를 믿게 만든 부분
변동성 예측은 마음먹으면 점수를 부풀리기 쉽다. 내일을 맞히면서 내일 데이터를 슬쩍 보면(look-ahead) 정확도가 환상적으로 나오고, 전부 가짜다. 그래서 막아둔 장치들.
- 미래 차단: 내일(t+1) 예측에 t까지의 정보만 사용
- 타깃은 strict forward, 피처는 전부 t 이하
- walk-forward: 과거로 학습 → 미래 예측 → 한 칸 밀고 반복 (셔플 금지)
- 누수 체크: corr(오늘 변동성, 정답) = 0.69, 1.0이 아님
- 교차 확인: HAR ≥ XGBoost라는 결과 자체가 누수 없음의 방증
corr(오늘 변동성, 정답)이 0.69였다. 누수가 있었다면 1.0에 붙었을 텐데 그러지 않았다. 그리고 HAR이 XGBoost보다 크기 오차가 작다는 결과 자체가 깨끗함의 증거다. 틈이 있으면 보통 표현력 큰 ML이 먼저 그리로 점수를 부풀린다.
남는 것
이 데이터는 일봉 OHLC뿐이라 변동성을 범위 기반 근사(Garman-Klass)로 잡았다. 실제 데스크는 5분봉 같은 분 단위 실현변동성을 쓰고, 그쪽이 타깃을 더 또렷하게 만든다. 분 단위로 내려가면 ML과 HAR의 거리가 좁혀질지 벌어질지는 지금 데이터로는 모른다.
크기는 HAR, 방향은 ML이라는 분업을 변동성 국면에 따라 모델을 갈아끼우는 규칙으로 바꾸면 둘 다 챙길 수 있을지도 모르겠다. 다음 편에서는 이 변동성 숫자를 옵션 헤지에 직접 먹여본다. 거기선 예측이 틀렸을 때 무슨 일이 벌어지는지가 진짜 질문이다.
Data: SPY/QQQ/AAPL daily OHLCV 2011–2026 (Yahoo). Target: forward Garman-Klass realized vol. Expanding-window walk-forward, quarterly refit, out-of-sample on back ~50%. Metrics averaged across 3 tickers, horizon = 1 day. ~3,770 trading days per ticker.